
導入
この記事は3部構成の2回目です。
前回の記事を読んでいなくても問題ありませんが、機械学習の基本概念について知りたい方は、1回目の記事も合わせてご覧いただくことをおすすめします。

第2回では、データセットの準備について紹介します。
本記事で紹介する機械学習モデル作成の基本的な進め方は以下の通りです。
- データの前処理
- データの用意
- データの整形
- トレーニングデータによる機械学習
- 整形データの読み込み
- TF-IDFを使った特徴量抽出
- 機械学習モデルの構築(Naive Bayes)
- 機械学習モデルのトレーニング
- トレーニングデータの評価
- 機械学習モデルの保存
- テストデータによる評価
- 機械学習モデルの読み込み
- テストデータの評価
これらのステップを順番に追っていきます。
機械学習の入門として最適なプログラムですので、ぜひ最後まで一緒に学びましょう!
環境
Javaバージョン:11(※1)
Wekaバージョン:3.8.6
※1:Java 12以上のバージョンを使用している場合、Wekaが正常に起動しない可能性があります。Wekaを利用する際は、Java 11またはそれ以前のバージョンでの実行をお勧めします。
データの前処理
データの用意
今回は「Large Movie Review Dataset(大規模な映画レビューデータセット)」を用いて、映画に対するレビューが「肯定的/否定的」なのかをテキスト分類する機械学習モデルを作成します。
データセットは、こちらのサイト(※2)から入手できます。
「Large Movie Review Dataset v1.0」をクリックすると、データセットのダウンロードが始まります。
データセットは、圧縮されているため、解凍してください。
筆者の場合、「.gz」と「.tar」で2回圧縮されていたため、2回解凍しました。
無事、解凍することができれば、データの用意は完了です。
※2:本データセットをブログや論文などで使用する際には、データセットのクレジットを明記する必要があることに注意して下さい。
利用データセット情報
- 作成者: Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher
- タイトル: Learning Word Vectors for Sentiment Analysis
- 公開日: Jun, 2011
- URL:http://www.aclweb.org/anthology/P11-1015
データの整形
これから、機械学習アルゴリズムがトレーニングおよびテストできるように、ダウンロードしたデータセットを整形していきます。
データセットの中身が下画像のようになっていることを確認してください。
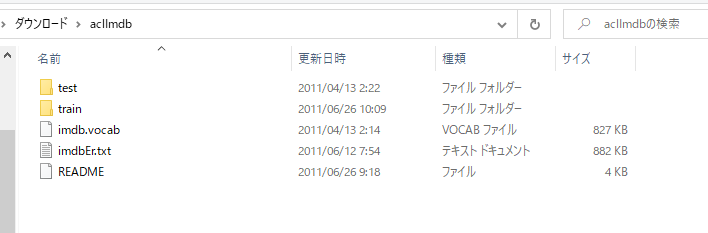
「train」フォルダに格納されているファイルを使用してモデルをトレーニングし、そして 「test」フォルダに格納されているファイルを使用してモデルを評価します。
機械学習アルゴリズムがトレーニングおよびテストできるようにするには、データを以下のように整形し、csvファイルなどに出力する必要があります。
text,category
Story of ~,negative
Airport 77 starts ~,negative
/*~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/一番上の行はヘッダーになります。
次の行からはデータセットの内容が続き、左列にはレビューの内容、右列には「肯定的/否定的」を示すカテゴリが記述されます。
では、さっそくデータセットの整形をしていきます。
以下は、データを整形するためのプログラムになります。
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import org.apache.commons.csv.CSVFormat;
import org.apache.commons.csv.CSVPrinter;
public class Sample1 {
public static void main(String[] args) throws IOException {
String inputFile_neg = "C:\\Users\\aclImdb\\train\\neg";
String inputFile_pos = "C:\\Users\\aclImdb\\train\\pos";
String outputFile = "C:\\Users\\aclImdb\\train.csv";
// CSV の形式を定義する
CSVFormat format = CSVFormat.Builder.create(CSVFormat.DEFAULT).setHeader("text", "category").build();
System.out.println("開始");
// 書き込み処理
try(FileWriter fw = new FileWriter(outputFile, StandardCharsets.UTF_8);
CSVPrinter csvPrinter = new CSVPrinter(fw, format);) {
// フォルダ内のファイルをすべて取得する
File folder_neg = new File(inputFile_neg);
File[] files_neg = folder_neg.listFiles();
// 各ファイルを読み込む
for (File file : files_neg) {
//テキストの読み込み
String text = Files.readString(file.toPath());
//データを書き込み
csvPrinter.printRecord(text.replace("\"", "").replace("'", ""), "negative");
}
// フォルダ内のファイルをすべて取得する
File folder_pos = new File(inputFile_pos);
File[] files_pos = folder_pos.listFiles();
// 各ファイルを読み込む
for (File file : files_pos) {
//テキストの読み込み
String text = Files.readString(file.toPath());
//データを書き込み
csvPrinter.printRecord(text.replace("\"", "").replace("'", ""), "positive");
}
}
System.out.println("終了");
}
}以下の結果が出力されれば、プログラム終了になります。
開始
終了train.csvが作成されていることを確認してください。
ファイルサイズが大きいため、開いて中を確認する必要はないです。
プログラムについて、少しだけ補足になります。
//データを書き込み
csvPrinter.printRecord(text.replace("\"", "").replace("'", ""), "negative");ここでは、テキストファイルに含まれるcsvの区切り文字を除去するため、区切り文字となる「\(バックスラッシュ)」「’(セミコロン)」を削除しています。
これにより、「text」と「category」の2列のデータセットを作成することができます。
本プログラムをtestフォルダに対しても実行してください。
その際、出力ファイル(outputFile)の名前も変更することを忘れないでください。
データの前処理はここで終了となります。
次の記事からは、いよいよWekaを用いた機械学習の紹介になります。
ぜひ、次の記事も読んでください。
コメント