
導入
この記事は3部構成の3回目になります。
第1回目では、機械学習の基本的なステップについて、
第2回目では、機械学習の最初のステップであるデータセットの前処理について、プログラムも交えて紹介しています。
第1回目を読んでいなくても問題はありませんが、第2回目については、一読することをお勧めします。

第3回目では、Wekaを使用して機械学習を行い、生成されたモデルの評価を行います。
途中、難しい箇所があるかもしれませんが、一緒に最後まで学んでいきましょう!
機械学習モデル作成のプログラム紹介
プログラム全体
import java.io.File;
import weka.classifiers.Evaluation;
import weka.classifiers.bayes.NaiveBayes;
import weka.core.Instances;
import weka.core.converters.CSVLoader;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.StringToWordVector;
public class Sample2 {
public static void main(String[] args) throws Exception {
String inputFile = "C:\\Users\\aclImdb\\train.csv";
System.out.println("開始");
// 1. データの読み込み
CSVLoader loader = new CSVLoader();
loader.setFile(new File(inputFile));
Instances data = loader.getDataSet();
data.setClassIndex(data.numAttributes() - 1);
// 2. データをシャッフル
Resample resampleFilter = new Resample();
resampleFilter.setRandomSeed(1); // シード値を指定
resampleFilter.setInputFormat(data);
Instances shuffledData = Filter.useFilter(data, resampleFilter);
// 3. TF-IDFを使った特徴量抽出
StringToWordVector filter = new StringToWordVector();
filter.setInputFormat(shuffledData);
filter.setTFTransform(true); // TF を使用
filter.setIDFTransform(true); // IDF を使用
Instances filteredData = Filter.useFilter(shuffledData, filter);
// 4. 分類モデルの構築 (Naive Bayesを使用)
NaiveBayes classifier = new NaiveBayes();
// 5. 分類モデルのトレーニング
classifier.buildClassifier(filteredData);
// 6. モデルの評価
Evaluation eval = new Evaluation(filteredData);
eval.crossValidateModel(classifier, filteredData, 20, new java.util.Random(1));
// 7. 分類結果の表示
System.out.println(eval.toSummaryString());
System.out.println("終了");
}
}開始
Correctly Classified Instances 20093 80.372 %
Incorrectly Classified Instances 4907 19.628 %
Kappa statistic 0.6074
Mean absolute error 0.3733
Root mean squared error 0.389
Relative absolute error 74.664 %
Root relative squared error 77.8064 %
Total Number of Instances 25000
終了プログラムの解説
1. データの読み込み
// 1. データの読み込み
CSVLoader loader = new CSVLoader();
loader.setFile(new File(inputFile));
Instances data = loader.getDataSet();「CSVLoader」を使ってCSV形式のデータを読み込み、作成したトレーニングデータを全て「data」に格納しています。
data.setClassIndex(data.numAttributes() - 1);「setClassIndex」メソッドは、dataに格納されたトレーニングデータ内、特徴の列がどれであるかを指定する処理です。
特徴とは、分類したいクラス属性を表す情報になります。
今回の場合、特徴は「text(レビュー)」、クラス属性が「category(肯定的/否定的)」になります。
2. データをシャッフル
// 2. データをシャッフル
Resample resampleFilter = new Resample();
resampleFilter.setRandomSeed(1); // シード値を指定
resampleFilter.setInputFormat(data);
Instances shuffledData = Filter.useFilter(data, resampleFilter);ここでは、dataに登録されたトレーニングデータの順番をシャッフルしています。
トレーニングデータをシャッフルする理由は、データの偏りがモデルの学習に影響を及ぼすのを防ぐためです。
今回の場合、トレーニングデータのCSVファイルは、前半が「negative」、後半が「positive」という順序で並んでいます。
この順序が偏っているため、データのシャッフルを行います。
なお、本プログラムにおいてデータのシャッフルを行わない場合、約30%もモデルの評価結果が変化しました。
3. TF-IDFを使った特徴量抽出
// 3. TF-IDFを使った特徴量抽出
StringToWordVector filter = new StringToWordVector();
filter.setInputFormat(shuffledData);ここでは、テキストデータ「shuffledDate」の単語をベクトル値に変換して、機械学習モデルがトレーニングするためのデータを準備をしています。
具体的には、「setInputFormat」メソッドを使用して、単語をベクトル値に変換するための「shuffledData」フォーマットを「filter」に設定しています。
filter.setTFTransform(true); // TF を使用
filter.setIDFTransform(true); // IDF を使用「setTFTransform(true)」は、単語をベクトル値に変換する際の計算方法として「TF」を設定しています。
「setIDFTransform(true)」は、単語をベクトル値に変換する際の計算方法として「IDF」を設定しています。
Instances filteredData = Filter.useFilter(shuffledData, filter);「useFilter」は、「filter」に設定した内容に従い、単語をベクトル値に変換しています。
4. 分類モデルの構築 (Naive Bayesを使用)
// 4. 分類モデルの構築 (Naive Bayesを使用)
NaiveBayes classifier = new NaiveBayes();分類モデルに「Naive Bayes(単純ベイズ分類器)」を選択します。
Naive Bayesは、あるデータがどのカテゴリーに属するのかを判定する機械学習の分類モデルのひとつです。
5. 分類モデルのトレーニング
// 5. 分類モデルのトレーニング
classifier.buildClassifier(filteredData);「buildClassifier」メソッドを使用して、TF-IDFで特徴抽出したトレーニングデータを学習させています。
6. モデルの評価
// 6. モデルの評価
Evaluation eval = new Evaluation(filteredData);
eval.crossValidateModel(classifier, filteredData, 20, new java.util.Random(1));交差検証によりモデルを評価します。
ここでは、20分割交差検証を行っています。
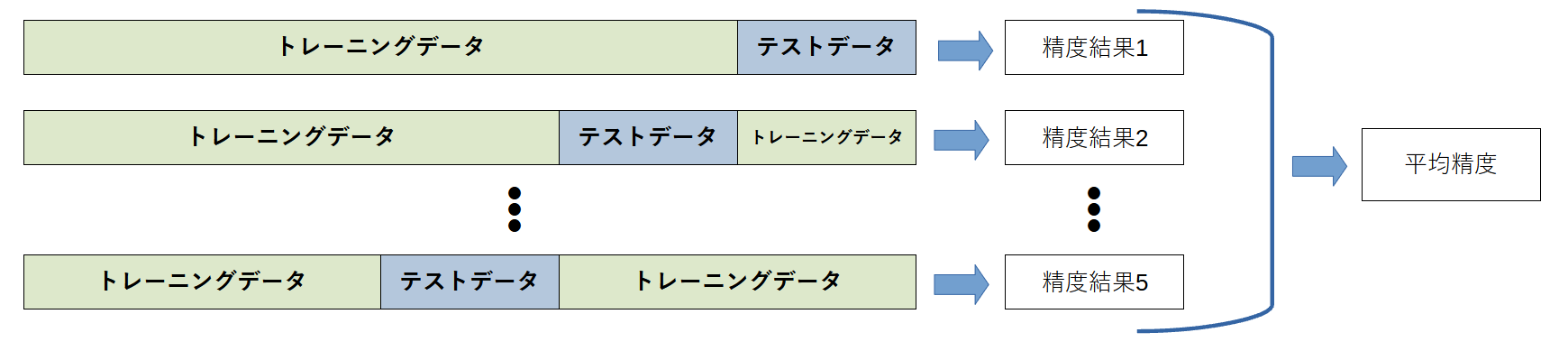
交差検証とは、データを複数分割してモデルを評価する手法です。
このケースでは、トレーニングデータを20分割し、それぞれのデータセットをテストデータとして機械学習モデルを評価します。
最終的に、20回の評価結果を平均してモデルの性能を算出します。
5分割の交差検証の場合、以下のイメージで機械学習モデルを評価します。
7. 分類結果の表示
// 7. 分類結果の表示
System.out.println(eval.toSummaryString());「toSummaryString」メソッド で分類結果の要約を表示します。
分類結果から機械学習モデルの正解率は約80%になります。
この結果は、はっきりと言って悪いです。
通常、トレーニングデータで学習した機械学習モデルは、ほぼ100%の正解率を達成します。
そのため、本機械学習モデルは、特徴抽出(TF-IDF)や分類モデル(Naive Bayes)などに修正が必要だと考えられます。
詳しい計算などは抜きにして、表示された評価の簡単な説明を以下に記載します。
- Correctly Classified Instances:正しく分類されたテストデータの数。
- Incorrectly Classified Instances:誤って分類されたテストデータの数。
- Kappa statistic:ランダム分類と比較して、機械学習モデルがどれだけ優れているかを示す値。
- Mean Absolute Error:平均絶対誤差のことで、テストデータの予測値と正解値の差を絶対値で計算し、それらの誤差をテストデータの総数で割って平均を取った指標。
- Root Mean Squared Error(RSME):2乗平均平方根誤差のことで、各予測誤差を二乗し、その総和の平均を取って、平方根を計算したものです。
\( RSME = \sqrt{\dfrac{1}{N}\sum^{N}_{i=1}(y_i-\bar{y_i})^{2} }\)
- Relative Absolute Error:相対絶対誤差のことで、予測値と正解値の絶対誤差を正解値の合計に対して比較した値。
- Root Relative Squared Error:モデルの予測値と正解値の差の二乗誤差の平均を、正解値の範囲で正規化した指標で、モデルの予測精度を相対的に評価。
0に近いほど優れたモデルを示す。
- Total Number of Instances:データの総数。
まとめ
ここまで3回に記事を分けて機械学習の概要とプログラムについて学びました。
今回作成した機械学習モデルは、学習済みのトレーニングデータでしたが、学習していないテストデータに対して、正答率がどれくらいなのか今後確認したいと思います。
それにしても、機械学習モデルの多様性は理解していましたが、評価方法もこのように多岐にわたることには驚きました。
これからも、まだまだ勉強が必要そうです。
今後も機械学習に関する記事を定期的に投稿する予定です。
記事に関する何かご要望がある場合は、ぜひコメントしてください。
コメント